K-Means with Hadoop-like interface
We explain the streaming functionality of MRStreamer by looking at the K-Means algorithm. The details of the algorithm have already been discussed in the following article:
Joos-Hendrik Böse, Artur Andrzejak, Mikael Högqvist: Beyond Online Aggregation: Parallel and Incremental Data Mining with Online MapReduce,
ACM Workshop on Massive Data Analytics over the Cloud (MDAC 2010) at WWW2010, Raleigh, North Carolina, USA, April 26, 2010 [presentation][paper]
Essence of the algorithm
We state the essence of the iterative K-Means algorithm to help readers understand the MapReduce source code shown below.
The algorithm works iteratively in several steps, which are going to address in the following:
- In the first step, the mappers read their share of the input data and compress the original data set into a smaller data set, the so-called auxiliary clusters. These auxiliary clusters help to represent the original data in case of a limited size of main memory.
- Each mapper creates k initial clusters from these auxiliary clusters, which are later sent to the reducer.
- The (single) reducer merges the clusters from each mapper and recomputes the centroids of all k clusters.
- These centroids are now streamed back to the original mappers via a broadcast operation.
- Each mapper can now use the new centroids to reassign its auxiliary clusters to these centroids. The mappers send their local clusters back to the reducer.
- The reducer will merge the clusters again and recompute the centroids.
- This procedure is repeated until the reducer decides to stop resending data to the mappers. This usually happens when the algorithm converges.
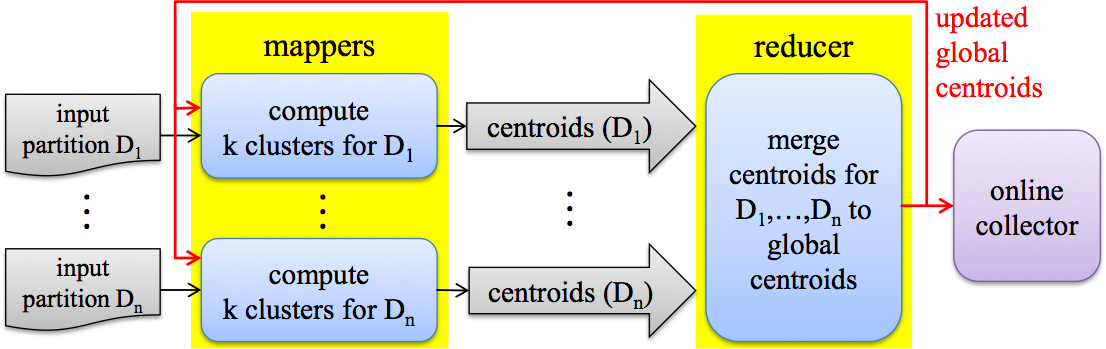
Illustration
The figure below illustrates the online and iterative K-Means algorithm implemented with MRStreamer.
Source code of K-Means
This source code and auxiliary classes can be found in the distribution file in the "examples" directory.
package examples;
import algorithms.kmeans.Cluster;
import algorithms.kmeans.Clusters;
import algorithms.kmeans.SamplesCache;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobContext;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.mahout.math.DenseVector;
import org.apache.mahout.math.DenseVectorWritable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
public class KMeansHadoop {
private final static Logger LOG = LoggerFactory.getLogger(KMeansHadoop.class);
public static class KMeansMapper extends
MRMapper<LongWritable, Text, IntWritable, Clusters, Clusters> {
private SamplesCache cache = new SamplesCache(500);
private int cacheSize = 10000;
private Clusters clusters = null;
private int k = 0;
private int nextCentroidToInit = 0;
/**
* Configures the mapper by reading two configuration options:
* - "numClusters": the k in k-Means
* - "numAuxClusters": the number of in-memory auxiliary clusters representing the input data
*
* @param context the mapper context, used to access the configuration
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
Configuration conf = context.getConfiguration();
this.k = conf.getInt("numCluster", 5);
this.clusters = new Clusters(k);
this.cacheSize = conf.getInt("numAuxCluster", 500);
this.cache = new SamplesCache(cacheSize);
}
/**
* Maps the input lines to initial centroids and, as a side-effect, stores auxiliary clusters representing the
* input data in memory
*
* @param key the key provided by the input format, not used here
* @param value one line of the input; input format: one data point per line, vector components delimited by spaces
* @param context the mapper context used to send initial centroids to the reducer
* @throws IOException
* @throws InterruptedException
*/
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// Input format: one data point per line, components delimited by spaces
final List<Double> doubleValues = new ArrayList<Double>();
final StringTokenizer tk = new StringTokenizer(value.toString());
while(tk.hasMoreElements()) {
final String token = tk.nextToken();
doubleValues.add(Double.parseDouble(token));
}
double[] dv = new double[doubleValues.size()];
for(int i=0; i<doubleValues.size(); i++) {
dv[i] = doubleValues.get(i);
}
DenseVector dvec = new DenseVector(dv);
DenseVectorWritable sample = new DenseVectorWritable(dvec);
// add sample to local auxiliary clusters
this.cache.addSample(sample);
// first k points are chosen as initial centroids
if (nextCentroidToInit < k) {
this.clusters.set(nextCentroidToInit, new Cluster(sample, sample));
this.nextCentroidToInit += 1;
} else if (nextCentroidToInit == k) {
// send initial centroids to reducer
context.write(new IntWritable(0), this.clusters);
this.nextCentroidToInit += 1;
}
}
/**
* Remaps the input data when a new set of preliminary clusters is received from the reducer by recalculating
* the assignment of the local input data, as represented by the auxiliary clusters, to the preliminary clusters
* and sends the updated centroids to the reducer.
* @param cs the preliminary clusters computed by the reducer
* @param context the mapper context used to send the locally recomputed centroids to the reducer
* @throws IOException
* @throws InterruptedException
*/
public void remap(List<Clusters> cs, Context context) throws IOException, InterruptedException {
LOG.info("Remapping preliminary clusters");
// set the preliminary clusters as new clusters
this.clusters = cs.get(0).clone();
this.clusters.reset();
// reassign the local input data, represented by the auxiliary clusters, to the clusters, thereby readjusting
// the clusters centroids
this.cache.reAssignAll(clusters);
// send the locally updated clusters to the reducer
context.write(new IntWritable(0), this.clusters);
}
}
public static class KMeansReducer extends
MRReducer<IntWritable, Clusters, IntWritable, Clusters, Clusters> {
private double lastError = Double.MAX_VALUE;
private float epsilon = Float.MAX_VALUE;
/**
* Configures the mapper by reading the configuration option "epsilon": The minimum change of the MSE needed to
* trigger a new iteration.
*
* @param context the reducer context, used to access the configuration
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
epsilon = conf.getFloat("epsilon", 100f);
}
/**
* Reduces a list of clusters locally computed by the mappers into a preliminary global set of clusters, which
* is then restreamed to the mappers, or, iff the MSE of the global set of clusters has not changed by more than
* epsilon since the last reduce invocation ends the iteration by emiting the final set of clusters.
*
* @param key the key set by the mapper, not used here
* @param values the list of locally computed clusters computed by the mappers
* @param context the reducer context, used to restream preliminary clusters to the mappers and emit the final
* clusters
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(IntWritable key, Iterable<Clusters> values,
MRReduceContext<IntWritable, Clusters, IntWritable, Clusters, Clusters> context) throws IOException, InterruptedException {
// Merge the list of clusters into one set of clusters
Clusters results = null;
for(Clusters clusters : values) {
if( results == null ) {
results = clusters;
} else {
results.merge(clusters);
}
}
Double error = results.getMSE();
LOG.info("Last error " + lastError + ", current error " + error);
if (lastError < Double.MAX_VALUE &&
error <= lastError + epsilon &&
error >= lastError - epsilon) {
// MSE has changed by less than epsilon: Emit final result
context.write(new IntWritable(0), results);
LOG.info("Final result written.");
} else {
// MSE has changed by more than epsilon: Send recomputed preliminary clusters to mappers to start a new
// iteration
this.lastError = error;
results.computeNewCentroids();
context.restream(results);
LOG.info("Preliminary result restreamed.");
}
}
}
/**
* Executes the streaming Hadoop MapReduce program
* @param args first arg is input path, second arg is output path
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setBoolean("mrstreamer.hadoop.streaming", true);
// has to be 1 to ensure the algorithm producing valid results
conf.setInt(JobContext.NUM_REDUCES, 1);
conf.setInt(JobContext.NUM_MAPS, 4);
conf.set("numCluster", "5");
conf.set("numAuxCluster", "500");
Job job = new MRSJob(conf, "kmeanshadoop");
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Clusters.class);
job.setMapperClass(KMeansMapper.class);
job.setReducerClass(KMeansReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}