Online and Iterative Capabilities of MRStreamer with Hadoop Interface
MRStreamer offers a streaming capability with a Hadoop-like interface. The advantage is that developers who know the Hadoop interface can easily adapt the streaming approach of MRStreamer.
Online Capability of MRStreamer
When using the online capability of MRStreamer, input data for the map tasks can be either read in from files or from data streams. These mappers output <key k, value> pairs periodically. Reducers output their results regularly (after having processed a specified amount of input). These partial results are collected and can be used to compute preliminary (or final) results.
The following figure shows the basic architecture of MRStreamer.
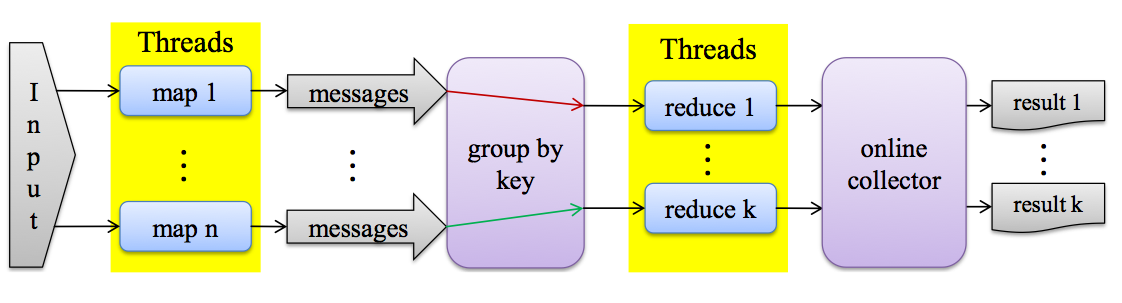
While the online computation is still running, the developer can use preliminary results by accessing the output data of MRStreamer, which is updated regularly. The preliminary results are written into a Hadoop-compliant output directory. The granularity of invoking reducers with preliminary mapper output is controlled by the buffer setting (below).
Buffering Mapper Results
The default behavior of a Hadoop-compatible MapReduce program is to buffer the complete mapper output before starting the reduce step. However, MRStreamer allows for online results during computation. To define how often preliminary results are send to reducers MRStreamer uses the configuration option "mrstreamer.reduceCollectorBufferSize". This size specifies the number of output items that need to be collected before being sent to the reducers. Thus, we can adjust how often the framework produces preliminary results.
Iterative Capability of MRStreamer
The iterative capability of MRStreamer works as follows:
- In the first step, the mappers process the input files and forward the processed data to the reducers. The reducers will first perform a regular reduce step, but instead of producing final results the preliminary results are fed back to the mappers. The difference here is that instead of the map function the remap function of each mapper is called.
- The mappers can use the preliminary results in the remap step and then forward new output data to the reducers.
- This procedure is repeated until the reducer decides to stop the iterative process by collecting the final results.
Data is kept at the mappers, which is more efficient than reloading each time.
API to Feed Data Back from Reducers to Mappers
To implement iterative algorithms MRStreamer extends the Hadoop API. In the initial map phase mappers produce output data. These data are sent to the reducer using context.write() (as done with Hadoop). The reducer collects the mapper data and computes a preliminary result. If the reducer decides to send results back to the mappers it calls the context.restream() method, which is specific to MRStreamer. To distinguish between the original map phase and later remap phases, the iterative mappers need to implement a remap method. This remap method is called when the reducer has issued context.restream(). If at some later point the reducer wants to finalize the computation, it calls context.write() instead of context.restream().
The following table summarizes the API calls need to implement iterative algorithms in MRStreamer.
| Mapper | Reducer | ||
|---|---|---|---|
| 1st iteration | input call | map() | reduce() |
| output call | context.write() | context.write() / context.restream() | |
| subseq. iterations | input call | remap() | reduce() |
| output call | context.write() | context.write() / context.restream() |
Defining Mapper and Reducer
To use the streaming mode of MRStreamer one needs to write the mapper and the reducer by extending two abstract classes:
- MRMapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT, REMAPIN>
The type parameters KEYIN, VALUEIN, KEYOUT, VALUEOUT define the input and output types of the mapper (similar to Hadoop). With the type parameter REMAPIN the user specifies the data type that is used in restreaming mode. - MRReducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT, REMAPOUT>
Similar to MRMappper the type parameters of MRReducer define the data type of keys and values for the reduce and remap step.
Example Skeleton of a Streaming-enabled MapReduce application
The streaming-enabled mapper of an MRStreamer application has the following form:
public static class MyMapper extends MRMapper<LongWritable, Text, IntWritable, Text, Text> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
}
@Override
public void remap(List<Text> valueList, Context context) throws IOException, InterruptedException {
}
}The streaming-enabled reducer of an MRStreamer application looks as follows:
public static class MyReducer extends MRReducer<IntWritable, Text, IntWritable, Text, Text> {
@Override
protected void reduce(IntWritable key, Iterable<Text> values,
MRReduceContext<IntWritable, Text, IntWritable, Text, Text> context) throws IOException, InterruptedException {
if( processingFinished ) {
context.write(new IntWritable(0), results);
} else {
context.restream(results);
}
}
}Iterative processing is possible with an Hadoop-like interface with only a small number of additional code.
The main program of such MRStreamer application is also very similar to Hadoop. The following source code shows such a main method.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInt(JobContext.NUM_REDUCES, 1);
conf.setInt(JobContext.NUM_MAPS, 4);
// IMPORTANT to enable streaming mode
conf.setBoolean("mrstreamer.hadoop.streaming", true);
Job job = new MRSJob(conf, "testapp");
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}